
科研进展
 所在位置: 首页»
科研进展
所在位置: 首页»
科研进展
稻米是全球最重要的农作物之一,及时、可靠和大规模的稻米产量估计对于制定国家粮食安全发展计划意义重大。国安院张朝教授团队在《Agricultural and Forest Meteorology》期刊发表论文,分别使用最小绝对收缩与选择算子(LASSO)回归,机器学习(随机森林,RF),以及深度学习(Long - Short- Term Memory Networks, LSTM)模型来预测中国县级水稻产量。
研究背景:
稻米(Oryza sativa L.)是全球最重要的农作物之一,占全球人口的50%以上。中国是世界上最大的稻米生产国(年产量约为2.06亿吨),占世界稻米生产的28%。水稻占中国粮食总产量的41%,仅占中国耕地面积的35%,是65%中国人口的主粮。然而,近年来水稻产量停滞不前。为了满足国内需求,中国需要在2030年之前将大米产量提高约20%。因此,及时,可靠和大区域的稻米估产将有利于政府制定科学合理的粮食安全发展计划,确保国家粮食安全。
近年来,许多产量估算方法仍然基于传统方法,包括面向过程的作物模型模拟以及基于作物产量和解释因素之间的统计模型。面向过程的作物模型,例如APSIM,WOFOST,DSSAT可以天为步长模拟作物的生长。然而,机理过程模型高度依赖于详实的土壤,田间管理以及天气等数据,对计算机计算性能也有巨大的要求。同时,品种,田间管理实践和环境(例如天气条件和土壤)具有高度的空间异质性,因此要实现大区域长时间尺度的估产具有极大的挑战,估算结果也存在很大的不确定性。此外,基于传统的统计方法——单产与自变量之间的特定响应函数,由于其更简单的计算和较高的解释力也是一种常用的估产方法。但是,由于传统的经验回归模型通常具有局限性和有限的空间泛化性,在实际应用中还存在许多问题。因此,有必要开发新方法来降低计算成本的同时还能提高估产精度,实现大范围、及时、精确的农作物估产。
创新点:
本研究调整三种机器/深度学习模型来预测水稻水稻产量,发现LSTM表现优于RF和LASSO模型;结合EVI和SIF用于预测水稻产量优于单独使用EVI或SIF。本研究开发了一个可扩展,简单和低成本的框架,可以用于快速预测水稻产量。
研究内容:
标题:
Integrating Multi-Source Data for Rice Yield Prediction across China using Machine Learning and Deep Learning Approaches
方法框架:
本研究采用三种具有代表性的基于统计的模型(即传统统计方法——LASSO,机器学习——RF,深度学习——LSTM)来预测每个水稻系统的水稻产量。分析分为四个步骤:(1)将所有选择变量和水稻产量归一化,并将整个数据集随机划分为训练数据(70%)和测试数据(30%);(2)仅针对训练数据集,基于最高R2和最低RMSE对每个模型的关键参数进行10倍交叉验证;(3)进行2011-2015年的“留一年”实验,利用R2和RMSE对模型的性能和泛化程度进行评价;(4)比较EVI、SIF和ESI在产量预测中的性能。不同的水稻系统有不同的输入变量。
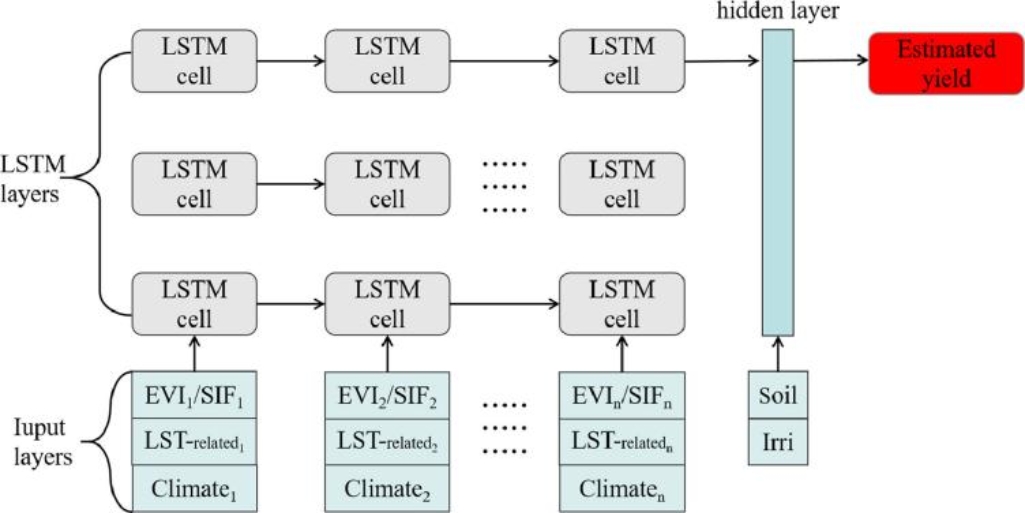
重要结果:
(一)各水稻系统的气候变量组合选择
由于自然条件和品种不同,各水稻系统的最佳气候变量组合也不同。图2为早稻产量预测的关键变量选择。注:(*)、(**)、(***)表示p值分别< 0.05、0.01、0.001的相关系数(r)。NGDD、HKDD、CKDD、Pdsi、Pre和Pet分别代表正常生长有效积温(◦C)、热致死积温(◦C)、冷致死积温(◦C)、帕尔默干旱严重指数、降水(毫米)和蒸散(毫米)。Vpd、Vap、Tmin和Tmax分别是指蒸汽压差(kPa)、蒸汽压(kPa)、最高温度(◦C)和最低温度(◦C)。模型最终选择了LST相关变量来捕捉主要水稻产区的温度变化;在早稻产量预测模型中选择了NGDD、HKDD、Pre、Pet和Vpd;在晚稻预测模型中选择NGDD、CKDD、Pre、Pet、Vap;选择NGDD、HKDD、CKDD、Pre、Pet预测单季稻产量。
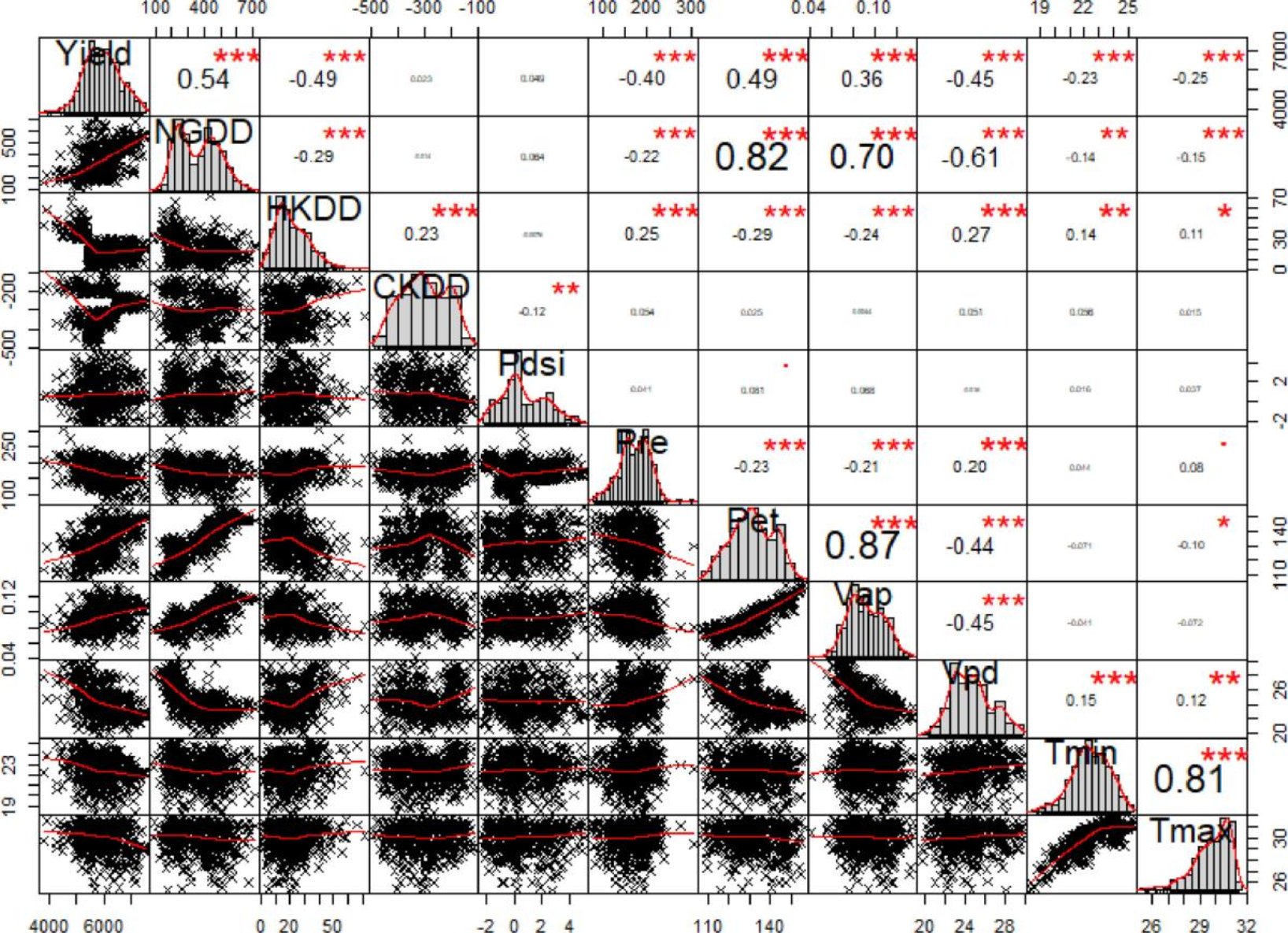
图2 早稻产量预测的关键变量选择
(二)时序变量与产量的时空相关分析
卫星植被指数EVI(图a,b)、SIF(图c,d)与单季稻和早稻(图a,c)、晚稻(图b,d)产量的时空相关性如图3。在箱形图中,水平线表示最大值和最小值;中间线表示中位数;上边缘和下边缘分别显示第75和第25百分位。相关性的空间格局以相关系数最高的月份(箱型图中的红点)展示。EVI和SIF都与水稻产量均呈正相关(除了生长期的最后月份,如7月和10月)且在作物生长“峰值”阶段相关性最高。在空间上,EVI和SIF在绝大部分区域均与产量呈显著正相关。

图3 卫星植被指数与水稻产量的相关性分布
共享气候变量NGDD(图a,b)、Pre(图c,d)、Pet(图e,f)与单季稻和早稻(a,c,e)、晚稻(b,e,f)产量的时空相关性如图4。独特气候变量HKDD(a,b)、CKDD(c,d)、Vap(f)、Vpd(g)与单季稻和早稻(a,c,e)、晚稻(b,e,f)产量的时空相关性如图5。产量与NGDD(图5a-b)、HKDD(图6b)和CKDD(图6d)之间的相关性大多为负相关,这是因为这三个气候指标都能捕捉到极端温度对产量的影响。除西南和东北地区小范围单稻体系外,产量与降水存在正均质相关关系,说明降水对产量有促进作用,尤其在生长“峰值”阶段。三种水稻体系的Pet、早稻的Vap、晚稻的Vpd等需水相关变量,与水稻产量相关性的空间格局在不同水稻系统之间存在明显差异,这可能是由于种植水稻的环境和生产系统的空间异质性。
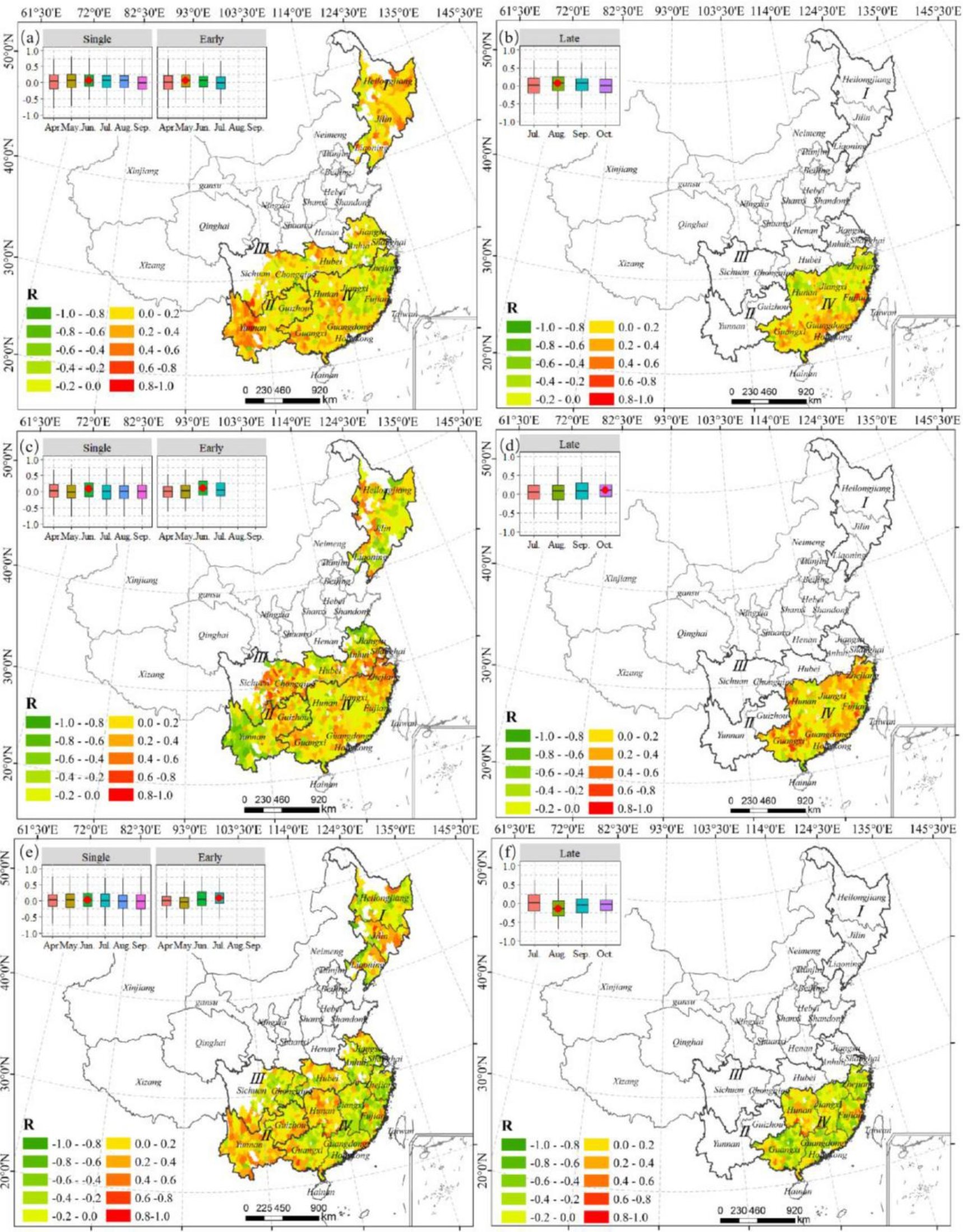
图4 共享气候变量与水稻产量的相关性分布
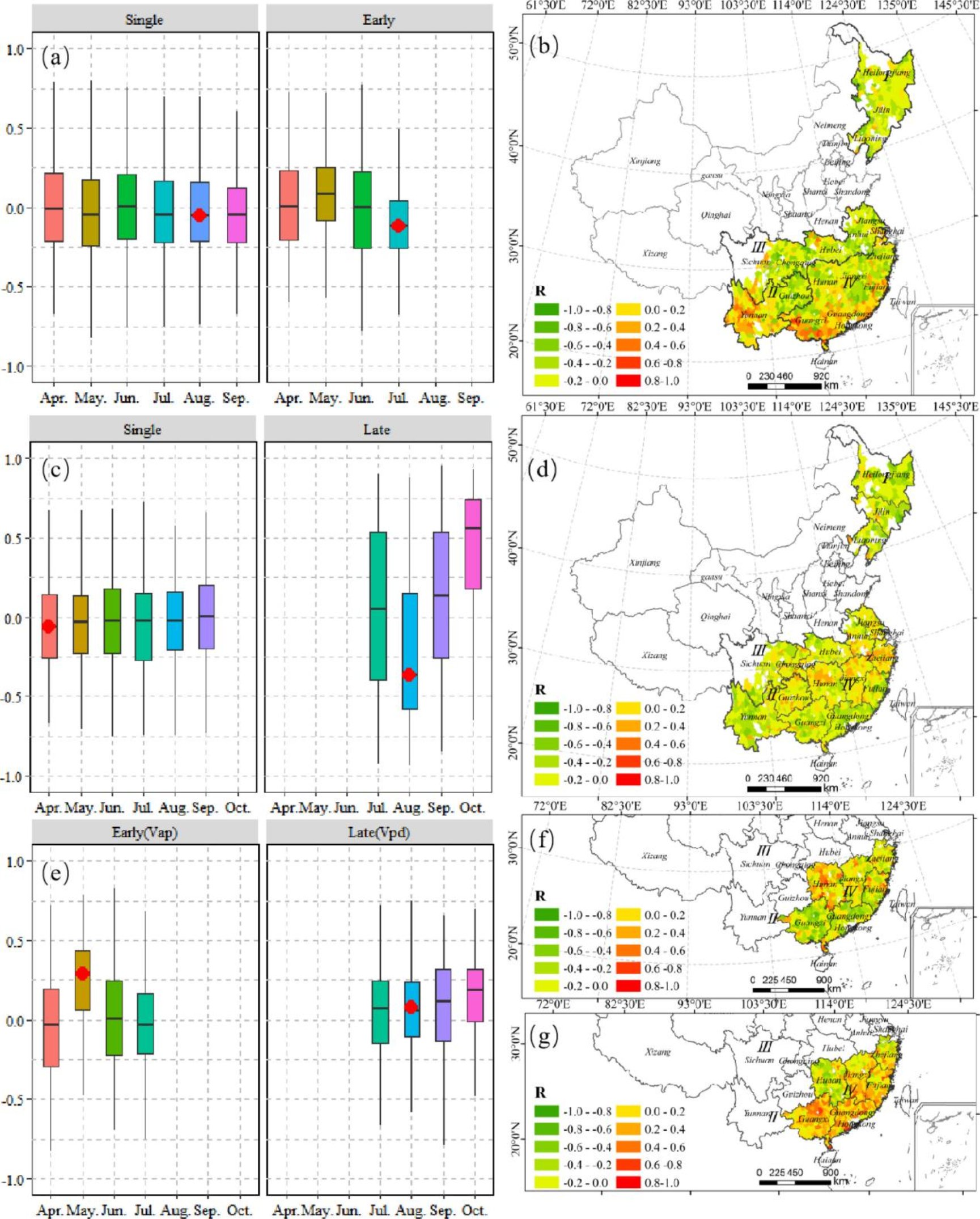
图5 独特气候变量与水稻产量的相关性分布
(三)集成不同卫星VIs对产量预测性能的贡献
在整个生长季使用不同VIs输入的三种模型R2和RMSE分别如图6和图7。随机测试数据集的误差线为R2的±15%。EVI、SIF和ESI分别代表增强植被指数、太阳诱导的叶绿素荧光和两者的组合。总体而言,ESI在预测县级水稻产量方面优于单独使用EVI和SIF,机器学习和深度学习方法明显优于传统的线性回归方法。因此,在接下来的分析中,使用ESI作为卫星植被指数输入,并使用两种非线性方法(即RF和LSTM)。
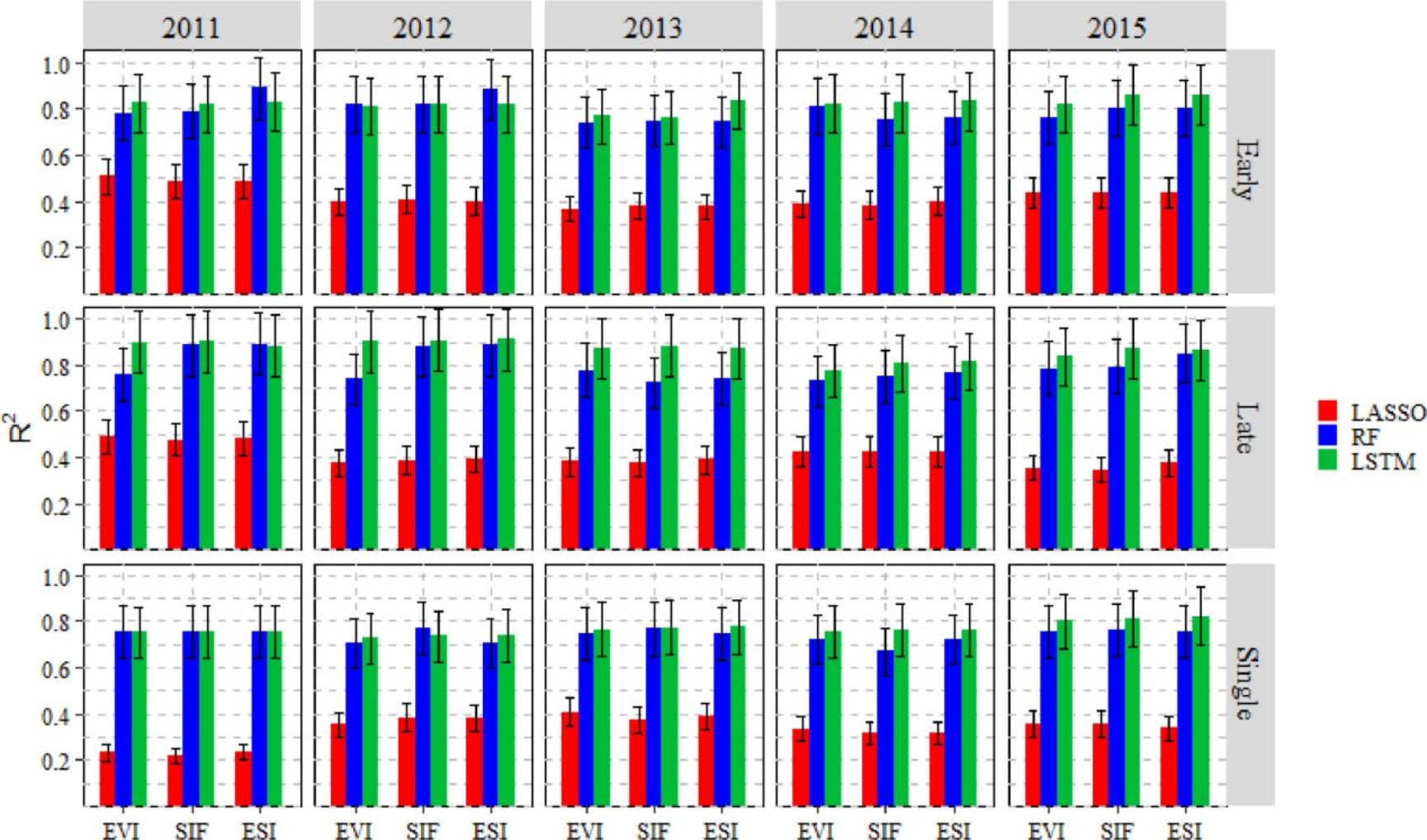
图6 各模型使用不同植被指数输入的R2
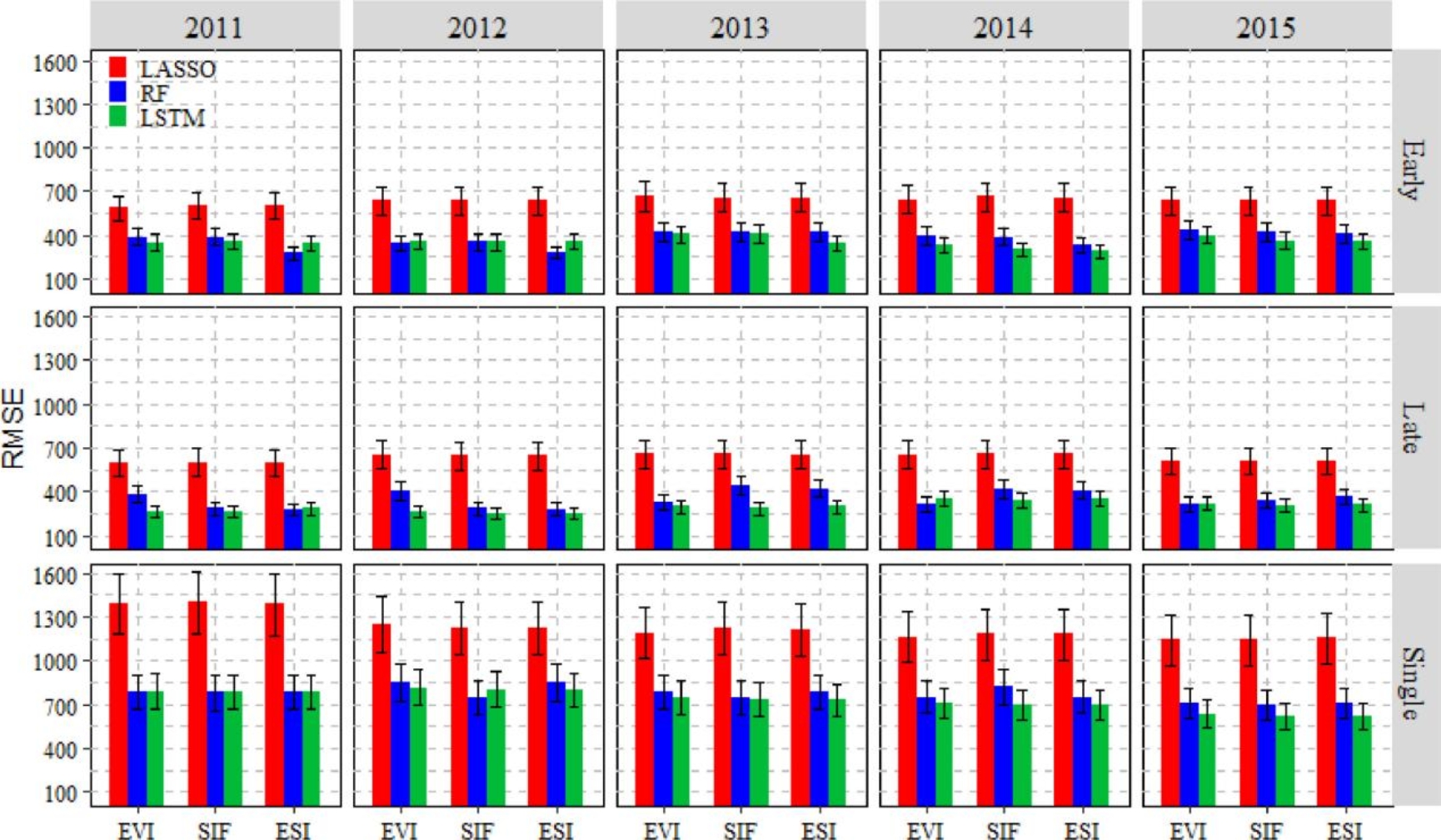
图7 各模型使用不同植被指数输入的RMSE
(四)ML和DL模型的县级季末预测技术
以2001~2014年的观测数据作为训练数据集,对2015年使用ML和DL模型进行预测,对每个水稻系统的产量预测性能进行了比较。散点图显示,县尺度上双季(即早稻和晚稻)的估计值和记录产量接近1:1线,而单季稻模型斜率总是小于1,这表明单季稻预测模型容易低估低产和/或高估高产。总体而言,LSTM模型在不同输入变量下的估产效果明显优于RF。
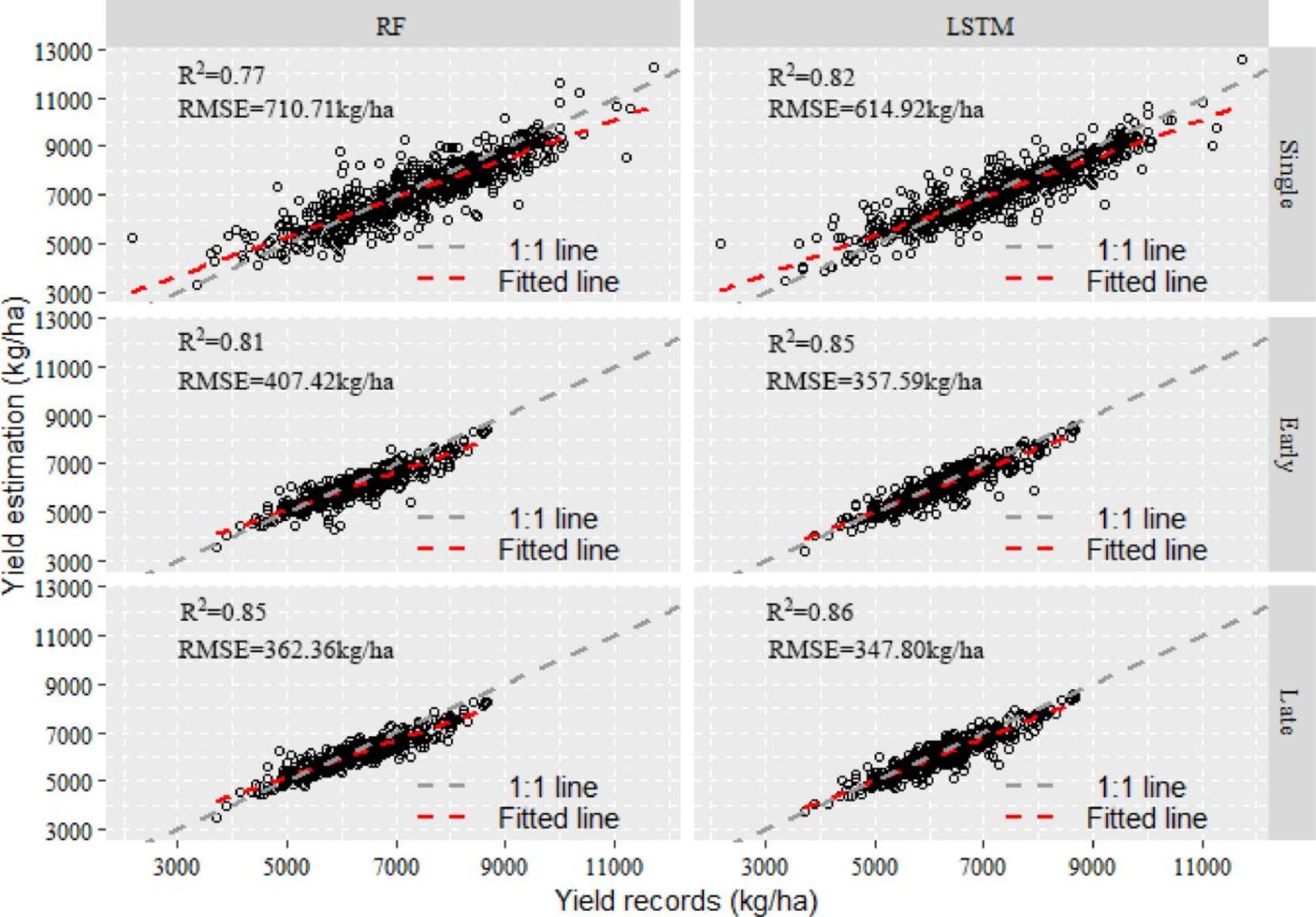
图8 2015年RF和LSTM估算产量与县尺度普查产量的散点图
通过RF (b和e)和LSTM (c和f)估计2015年产量的空间分布,以及2015年县尺度官方普查产量(a和d)如图9。图a-c代表单季稻和早稻,图d-f代表晚稻。在空间上,高产县主要分布在研究区南部,即中国南方的双季稻。而单稻制低产县则零星分布在研究区中部地区。2015年产量估算的空间格局与官方普查的产量相当吻合,尤其是LSTM模型;LSTM模型在一些高产县和低产县的表现优于RF模型。
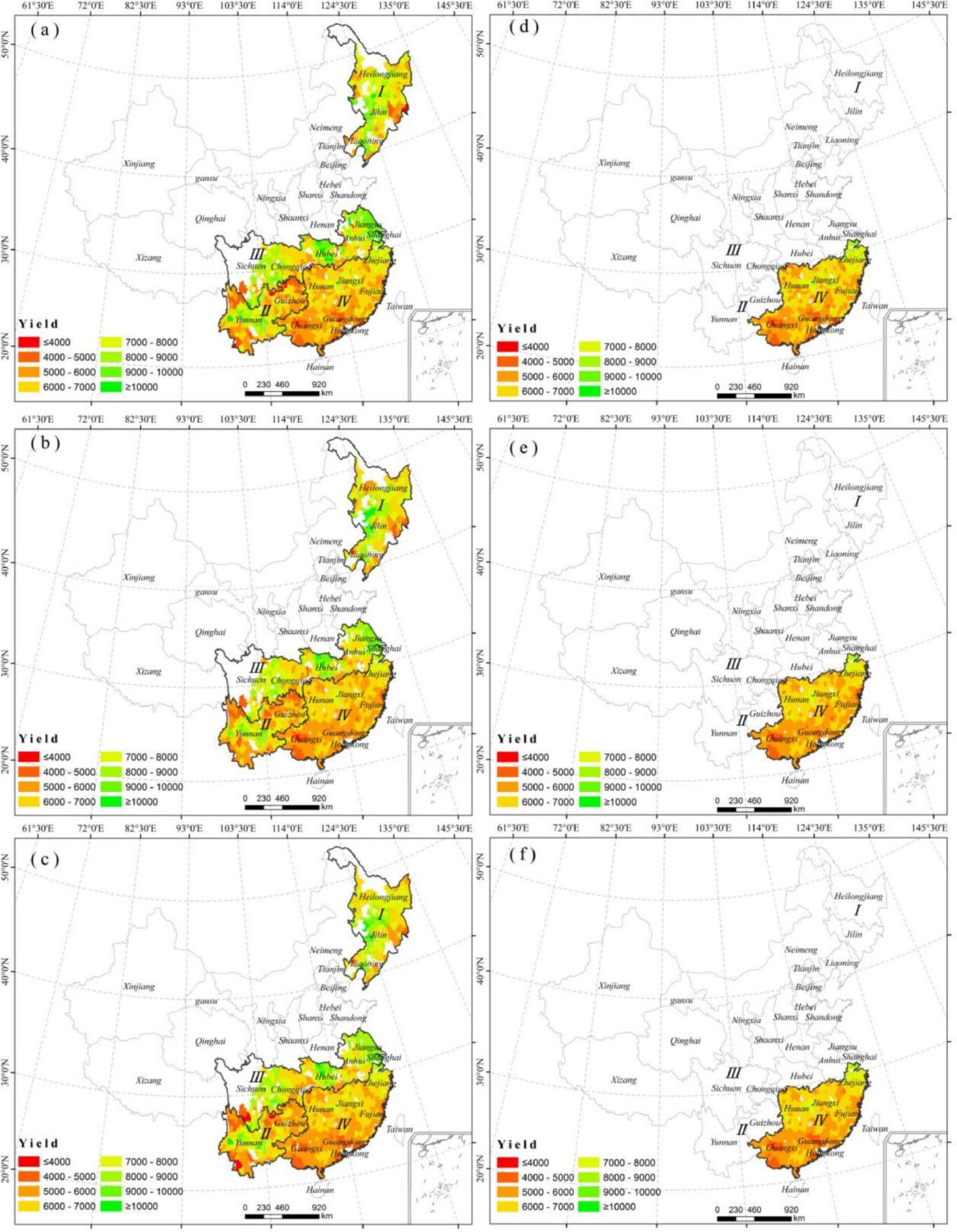
图9 官方普查产量和模型预测产量的空间分布
2015年单稻、早稻(a和b)和晚稻(c和d)的RF(a和c)和LSTM(b和d)模型预测结果的RMSE空间分布如图10所示。RF模型在整个研究区域产生了较大的正负误差(≥20%和≤-20%)且主要为正值,表明RF模型高估了2015年县级水稻产量。两种模型对单稻系统的高估主要分布在东北和云贵高原,这两个地区极端干旱和热胁迫发生频率较高。与RF相比,LSTM预测效果更佳,特别是在捕捉极端天气事件消极影响方面。
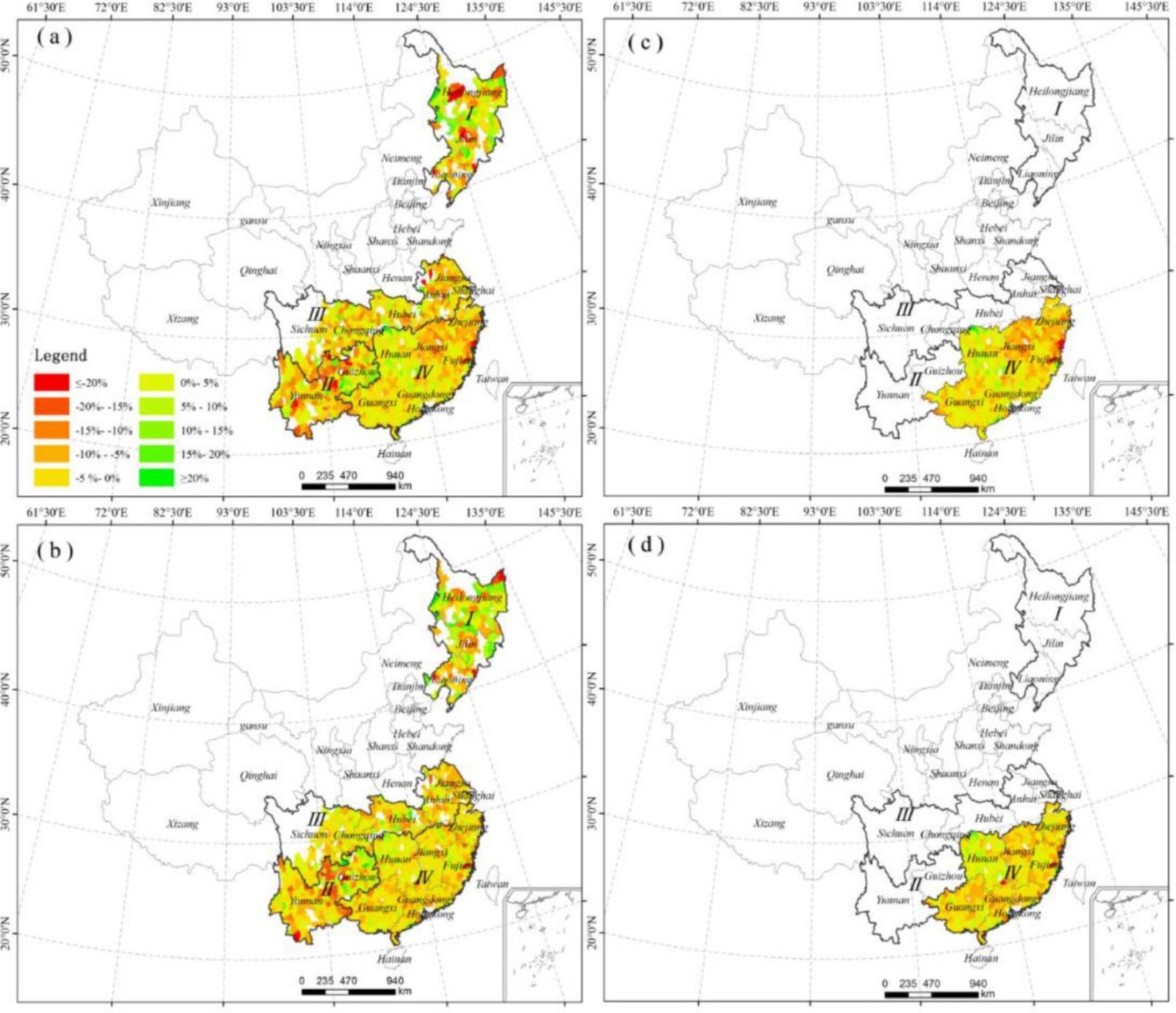
图10 模型预测结果的RMSE空间分布
(五)ML和DL模型的县级季末预测技术
在2015年对RF和LSTM方法在每个阶段的产量预测性能进行了比较,LSTM模型(a,c)与RF模型(b,d)的R2(a,b)和RMSE(c,d)如图11所示。总的来说,DL和ML的表现都随累积变量的增加而增加。LSTM模型通过在逐次阶段依次输入信息,在估计产量响应方面优于RF。各生长阶段所带来的效益和信息是不同的。在作物生长“峰值”阶段,两个模型的RMSE降低和R2增量最为显著,说明该阶段的信息对产量估算至关重要。“峰值”期是提高预测技术的关键时期,表明该模型在成熟前(单稻2个月左右,双稻1个月左右)即可达到较好的产量预测能力。
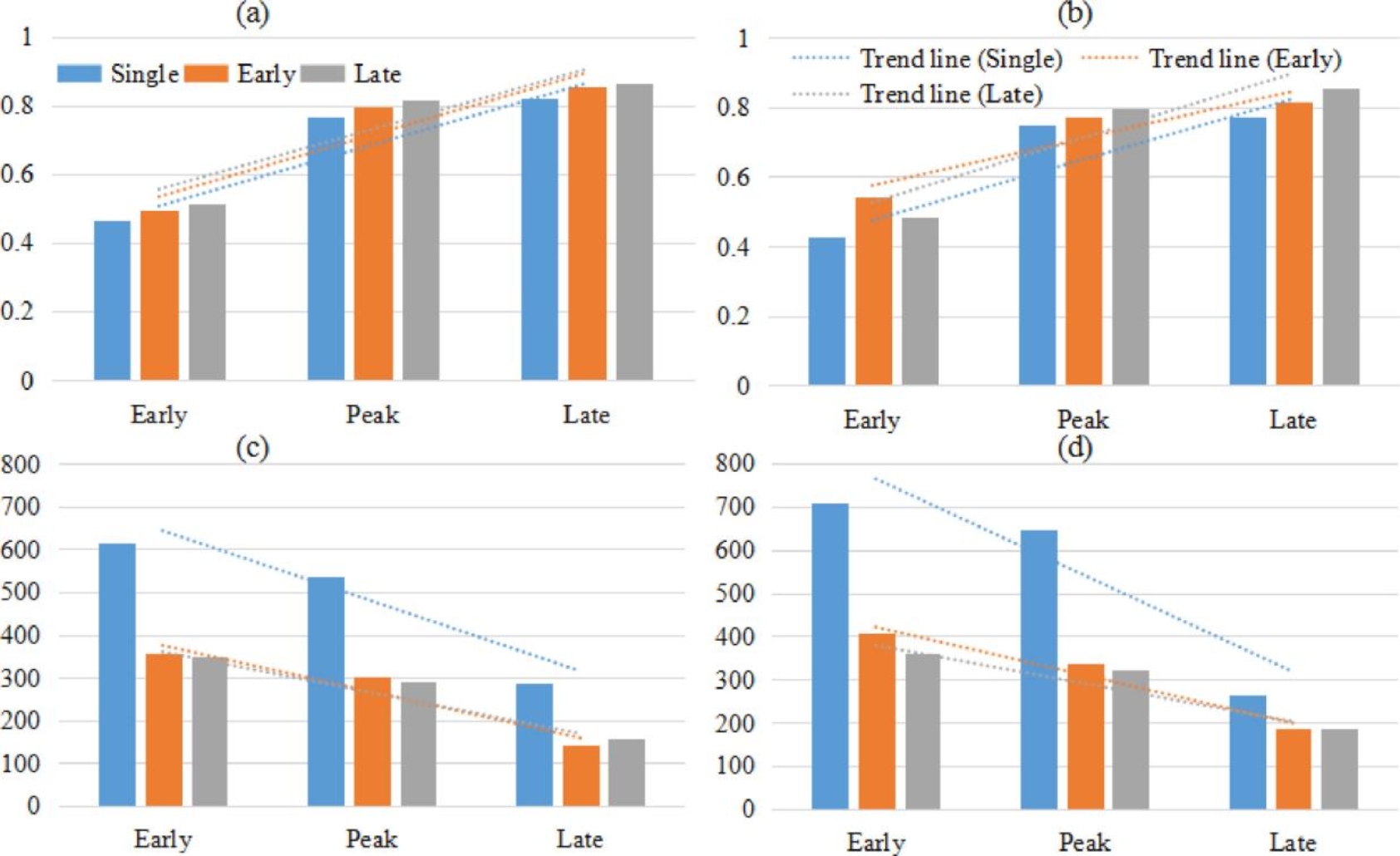
图11 2015年使用基于前向生长阶段的观测数据估算产量的模型表现
论文引用:
[1] Cao J, Zhang Z, Tao F, et al. Integrating multi-source data for rice yield prediction across china using machine learning and deep learning approaches[J]. Agricultural and Forest Meteorology, 2021, 297: 108275.
相关论文:
[1] Han J, Zhang Z, Cao J, et al. Prediction of winter wheat yield based on multi-source data and machine learning in China[J]. Remote Sensing, 2020, 12(2): 236.
[2] Cao J, Zhang Z, Luo Y, et al. Wheat yield predictions at a county and field scale with deep learning, machine learning, and google earth engine[J]. European Journal of Agronomy, 2021, 123: 126204.
[3] Zhang L, Zhang Z, Luo Y, et al. Combining optical, fluorescence, thermal satellite, and environmental data to predict county-level maize yield in China using machine learning approaches[J]. Remote Sensing, 2020, 12(1): 21.
[4] Zhang Z, Li Z, Chen Y, et al. Improving regional wheat yields estimations by multi-step-assimilating of a crop model with multi-source data[J]. Agricultural and Forest Meteorology, 2020, 290: 107993.
[5] Li L, Wang B, Feng P, et al. Crop yield forecasting and associated optimum lead time analysis based on multi-source environmental data across China[J]. Agricultural and Forest Meteorology, 2021, 308: 108558.
作者简介:
第一作者简介:曹娟,北京师范大学地理科学学部减灾与应急管理研究院博士研究生,研究方向为气候变化与粮食安全。
